
 |
| The hierarchical Domain Name System, organized into zones, each served by a name server |
When a system administrator wants to let another administrator control a part of the domain name space within his or her zone of authority, he or she can delegate control to the other administrator. This splits a part of the old zone off into a new zone, which comes under the authority of the second administrator's nameservers. The old zone becomes no longer authoritative for what goes under the authority of the new zone.
A resolver looks up the information associated with nodes. A resolver knows how to communicate with name servers by sending DNS requests, and heeding DNS responses. Resolving usually entails iterating through several name servers to find the needed information.
Some resolvers function simplistically and can only communicate with a single name server. These simple resolvers rely on a recursing name server to perform the work of finding information for them.
Parts of a domain name
A domain name usually consists of two or more parts (technically labels), separated by dots. For example wikipedia.org.- The rightmost label conveys the top-level domain (for example, the address en.wikipedia.org has the top-level domain org).
- Each label to the left specifies a subdivision or subdomain of the domain above it. Note that "subdomain" expresses relative dependence, not absolute dependence: for example, wikipedia.org comprises a subdomain of the org domain, and en.wikipedia.org comprises a subdomain of the domain wikipedia.org. In theory, this subdivision can go down to 127 levels deep, and each label can contain up to 63 characters, as long as the whole domain name does not exceed a total length of 255 characters. But in practice some domain registries have shorter limits than that.
- A hostname refers to a domain name that has one or more associated IP addresses. For example, the en.wikipedia.org and wikipedia.org domains are both hostnames, but the org domain is not.
Iterative and recursive queries:
- An Iterative query is one where the DNS server may provide a partial answer to the query (or give an error). DNS servers must support non-recursive queries.
- A recursive query is one where the DNS server will fully answer the query (or give an error). DNS servers are not required to support recursive queries and both the resolver (or another DNS acting recursively on behalf of another resolver) negotiate use of recursive service using bits in the query headers.
Address resolution mechanism
In theory a full host name may have several name segments, (e.g ahost.ofasubnet.ofabiggernet.inadomain.example). In practice, in the experience of the majority of public users of Internet services, full host names will frequently consist of just three segments (ahost.inadomain.example, and most often www.inadomain.example).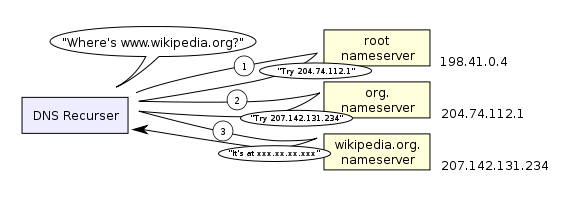 |
| A DNS recursor consults three nameservers to resolve the address www.wikipedia.org. |
For querying purposes, software interprets the name segment by segment, from right to left, using an iterative search procedure. At each step along the way, the program queries a corresponding DNS server to provide a pointer to the next server which it should consult.
As originally envisaged, the process was as simple as:
- the local system is pre-configured with the known addresses of the root servers in a file of root hints, which need to be updated periodically by the local administrator from a reliable source to be kept up to date with the changes which occur over time.
- query one of the root servers to find the server authoritative for the next level down (so in the case of our simple hostname, a root server would be asked for the address of a server with detailed knowledge of the example top level domain).
- querying this second server for the address of a DNS server with detailed knowledge of the second-level domain (inadomain.example in our example).
- repeating the previous step to progress down the name, until the final step which would, rather than generating the address of the next DNS server, return the final address sought.
The mechanism in this simple form has a difficulty: it places a huge operating burden on the root servers, with each and every search for an address starting by querying one of them. Being as critical as they are to the overall function of the system such heavy use would create an insurmountable bottleneck for trillions of queries placed every day. The section DNS in practice describes how this is addressed.
Circular dependencies and glue records
Name servers in delegations appear listed by name, rather than by IP address. This means that a resolving name server must issue another DNS request to find out the IP address of the server to which it has been referred. Since this can introduce a circular dependency if the nameserver referred to is under the domain that it is authoritative of, it is occasionally necessary for the nameserver providing the delegation to also provide the IP address of the next nameserver. This record is called a glue record.For example, assume that the sub-domain en.wikipedia.org contains further sub-domains (such as something.en.wikipedia.org) and that the authoritative nameserver for these lives at ns1.en.wikipedia.org. A computer trying to resolve something.en.wikipedia.org will thus first have to resolve ns1.en.wikipedia.org. Since ns1 is also under the en.wikipedia.org subdomain, resolving ns1.en.wikipedia.org requires resolving ns1.en.wikipedia.org which is exactly the circular dependency mentioned above. The dependency is broken by the glue record in the nameserver of wikipedia.org that provides the IP address of ns1.en.wikipedia.org directly to the requestor, enabling it to bootstrap the process by figuring out where ns1.en.wikipedia.org is located.
This article is licensed under the GNU Free Documentation License. It uses material from the Wikipedia.



